What is BEA ?
BEA stands for Bots Events Analysis. @VincentTerrasi coined the acronym on twitter and it fits well, so I use it also.
The goal is to analyze search engines bots in order to improve his website, his SEO.
Here, I’ll mainly show a preview of what we’re working on at Sem-Eye (see https://self.sem-eye.com).
I’ll insist on the visualization angle.
For now, those are mainly experiments based upon restricted data sets (some sites of our own, some clients).
Log analysis as a way to track bots
I will not explain the technical bases, I presume you already know that each web server (be it Apache Nginx or another one) writes logs for each requested url.
Those raw logs (and you don’t need any js marker, nor third-party solution) contain all you need to follow the paths and habits of web crawlers on your website.

So, we will filter out log lines according to the User Agent of each request, and only keep the lines we want to have a close look at.
In this article, we select either GoogleBot or Bing Bot.
Well, this is a rightful giving-back : the search engines (Qwant excepted) do all they can to track us and exploit our data : why wouldn’t we do the same ?
How does SEM Eye handle this ?
We are not big fans of number crunching for the sake of crunching, nor heavy lifting. We’re always trying to do it simple and efficient.
So, we take the raw log files, splitting them by week or month, according to what we want to see.
A small script filters out (very fast) this text file, and outputs a nice json file with everything we need, for each bot :
- Hits for each page
- Sessions for each bot, with the paths of each individual session
This is a reasonable sized file, that a browser can handle, in memory, without concerns.
This script could be open sourced later on.
We also plan to plug into an ElasticSearch database, if you already have a ELK or ELG stack (PaaS Logs from OVH does provide such a solution)
The visualizations from the lab
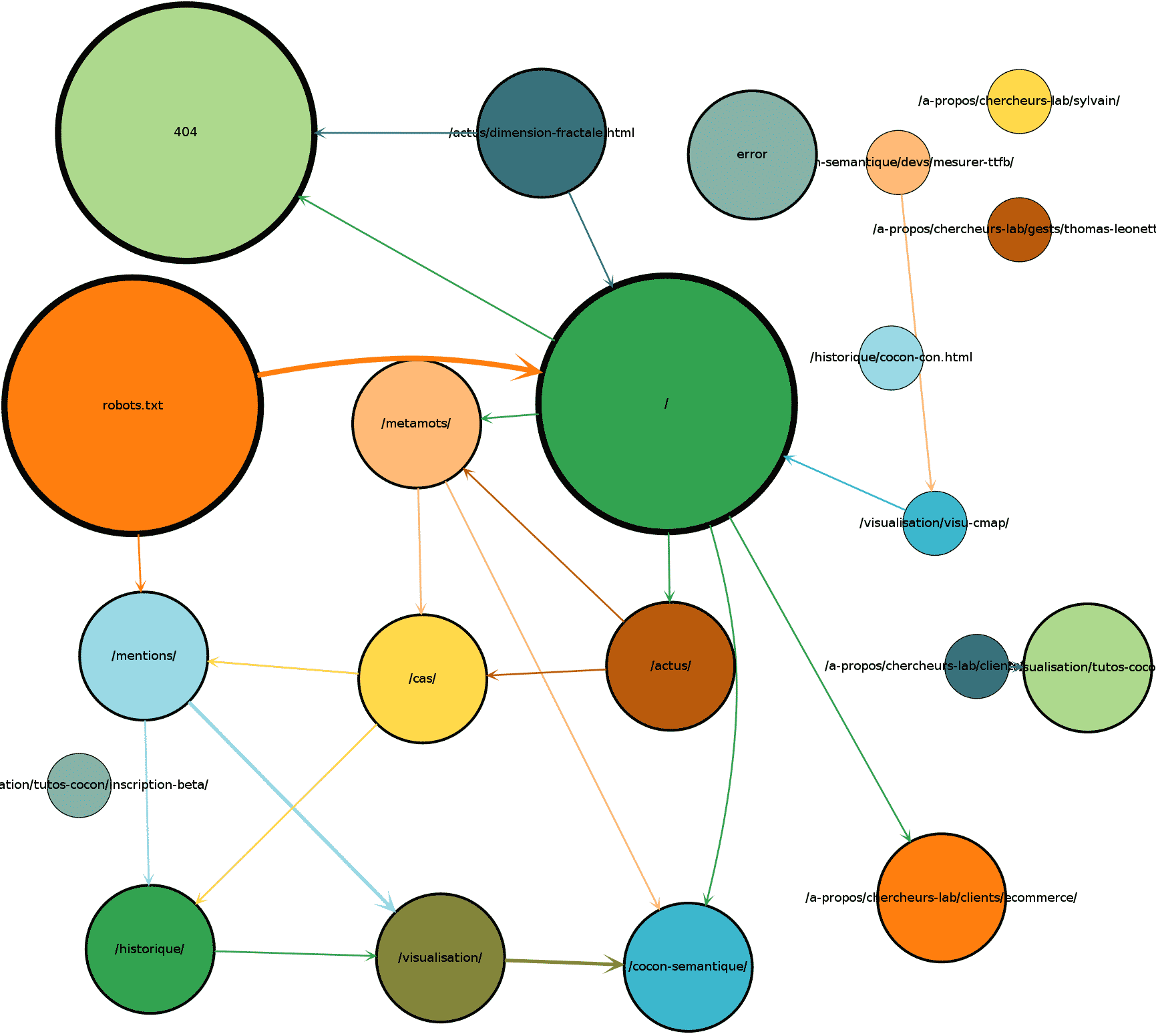
Those are just experiments, so we’ll keep it simple :
Each page is represented by a colored disk.
The disk radius is proportional to the hits of the page by the selected bot.
(I do not make the shape fit the url : this would give more visual importance to long url)
Then, I draw the “paths” that followed the bots within each session.
There, the more often a path is used, the bolder it is.
On the right, you can see what it gives for GoogleBot on Cocon.Se (the french version of this website), for a single week.
Underneath, you can see Googlebot again, but for a full month :
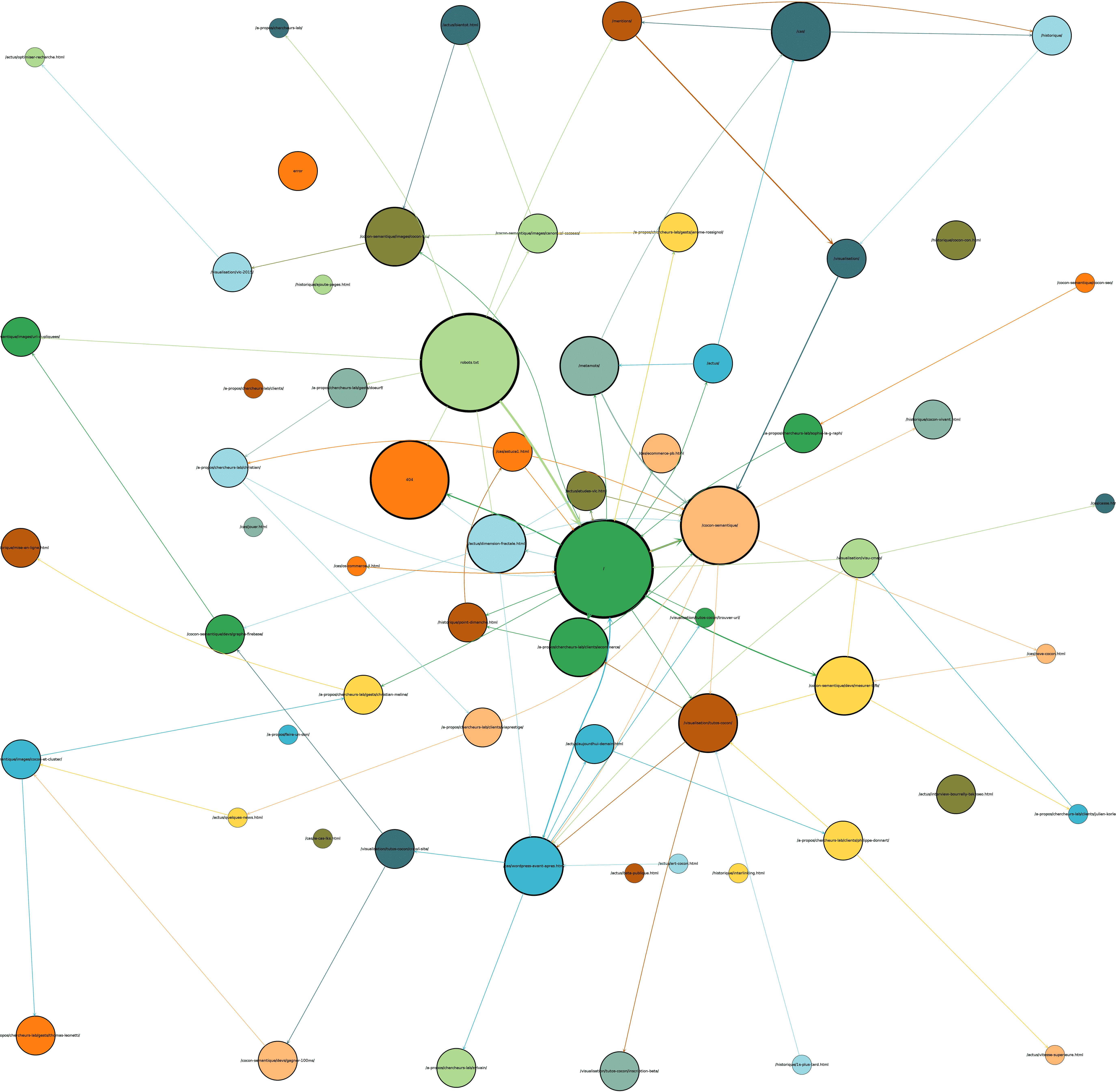
Matching with SEM Eye Views
Several things can be interpreted with those informations, but it’s not clearly organized, it lacks some stability, and you can’t see the pages that are NOT crawled by the bot : they are simply not in the dataset !!!
The following step is then to match those informations with the SEM Eye visualizations.
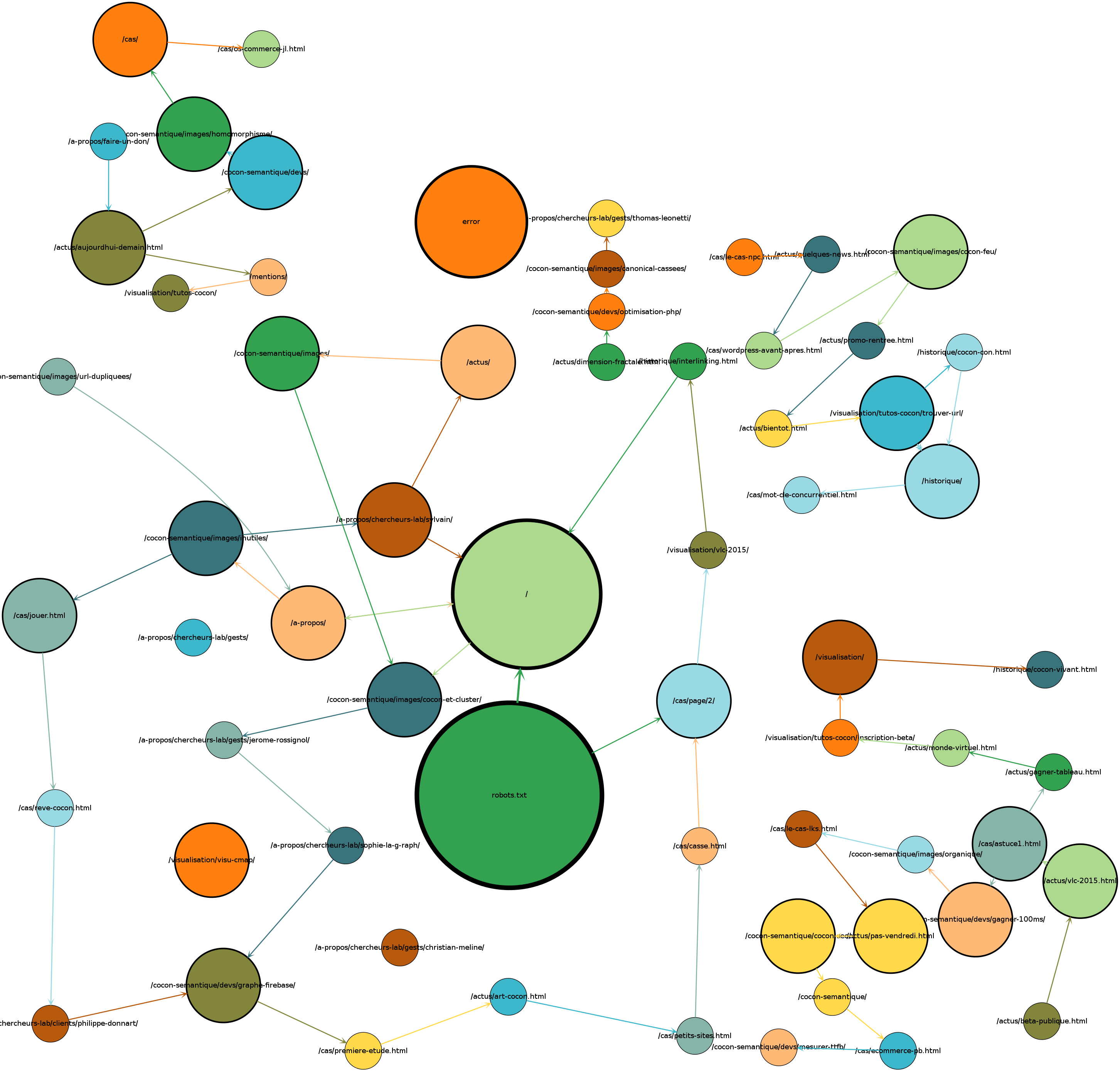
SEM Eye Visualization are meant to show you your website like Google sees it. We crawl and map your website, and produce a visual map of your site, organized by crawl level, url hierarchy aso.
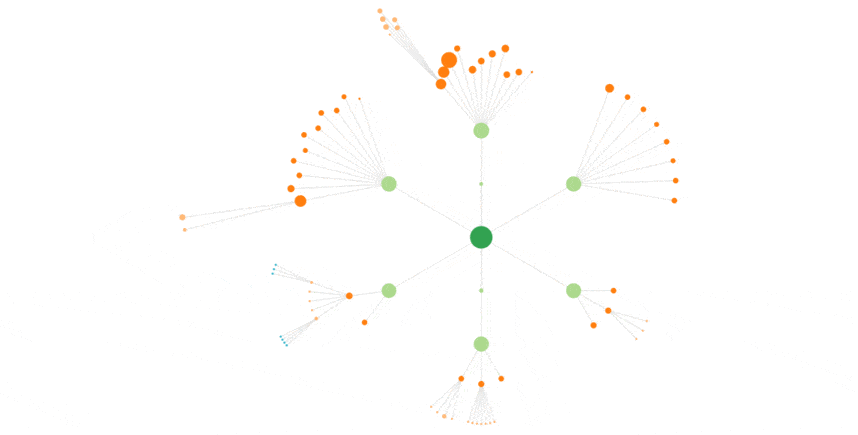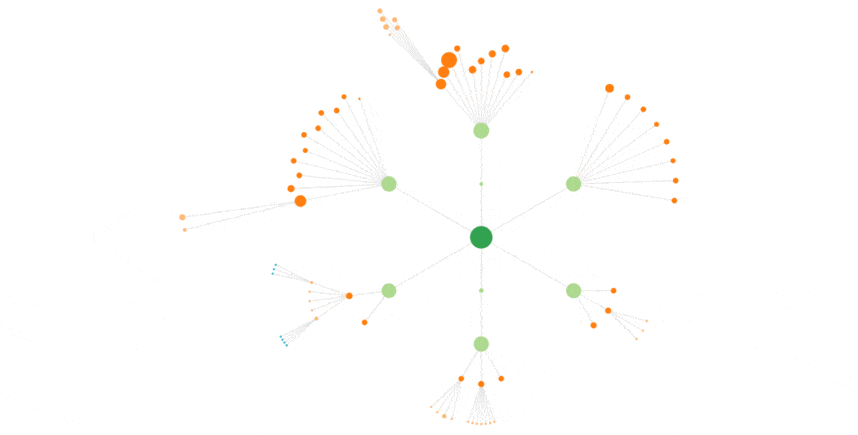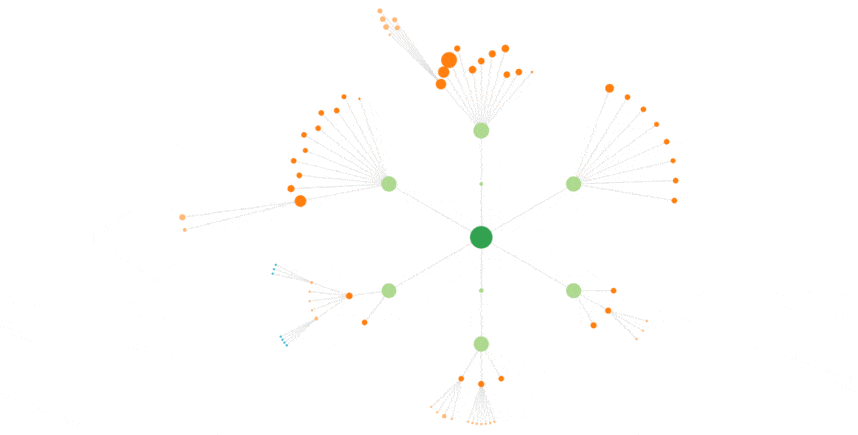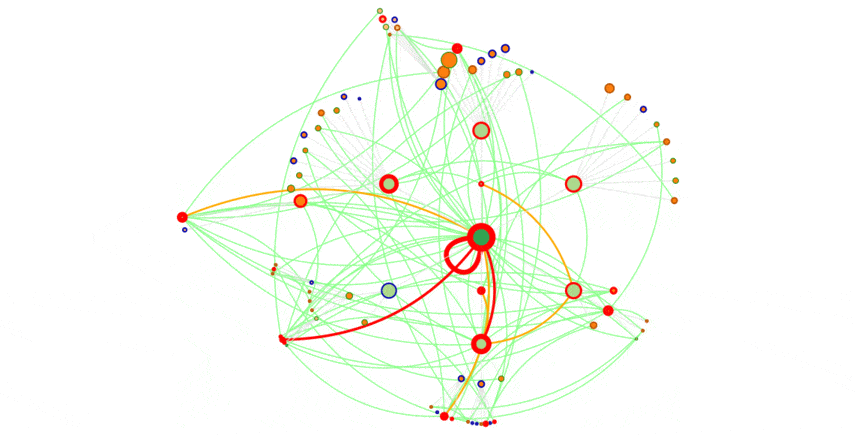
Let’s math the hits with the pages (here, we got a full week)
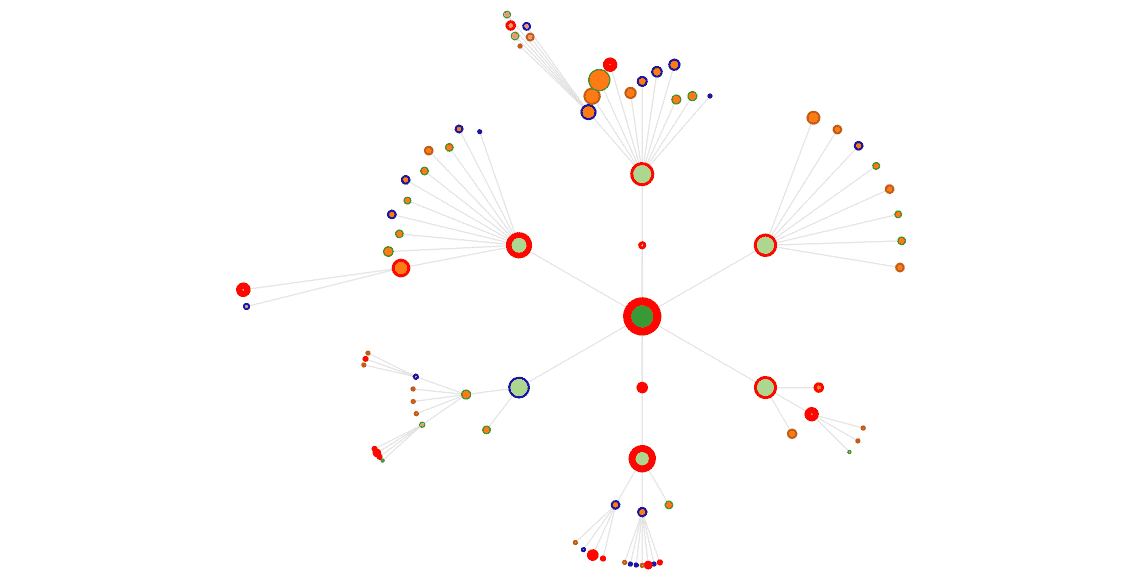
Blue border : pages that did not get any hit for the period
Green border : only one hit
Maroon border : 2 hits
Red border : 3 and more hits. The border gets bolder as the hit count grows.
On this composite view, we clearly see what pages get the most visits, we’ll get back to this later on.
With a click, we are able to display sessions and most frequent path.
Here is an animated snapshot (Sem Eye view, Hits view, Path views)
Googlebot, 3 weeks of log data :
Correlation with important pages
We were delighted to see that Googlebot crawled some pages way often than others.
It does consider some more important than others.
As a matter of fact, the pages that Google bot crawled often are nearly the same as the pages Sem Eye dod consider important.
The home page above all, then some category pages for instance.
Understanding of the bots behavior
With this composite view, there are many things to interpret.
For instance, We confirm that Google does crawl the fresh content pages (here, a fresh page got more hits than a “sister” one from the same level) and pages linked from it.
Google does recrawl a lot when we change the whole site internal linking.
One more remarkable thing is that, on a month period, nearly all pages are crawled at least one, it only crawled a small extract each week, but always with respect to the Internal PageRank : each week, it pays several visits to the home and categories, then a small portion of the remaining pages.
From one week to another, not much difference to see, but upon a whole month, all pages would have been crawled.
We also saw that a specific page, “about”, that is as important as it’s neighbours (speaking of the Internal PR), doesn’t get much visits.
This is a generic url, the page’s content was weak and did not change often : no reason to spend time there !
One more enlightening analysis is how the various bots behave differently.
For instance, Google bot seems way more optimized than Bingbot.
Google does spare it’s resources, and dedicate them to the “important” pages first.
Bing does crawl everything with more or less the same priority, with far less shades.
Here is the animation for Bing, with the same 3 weeks :
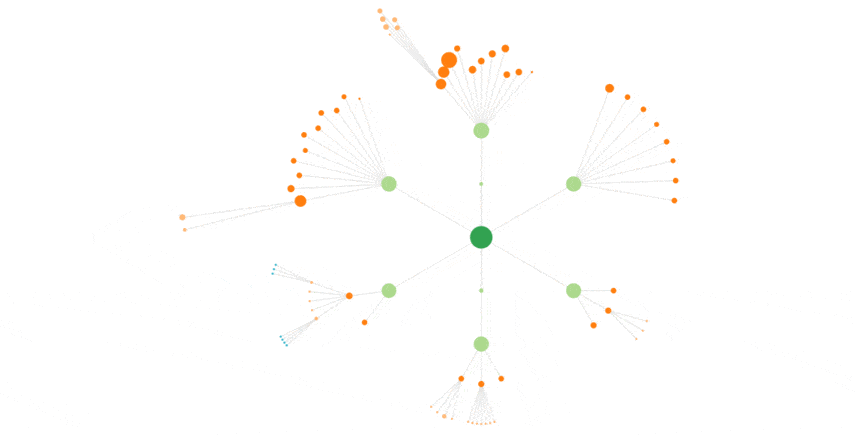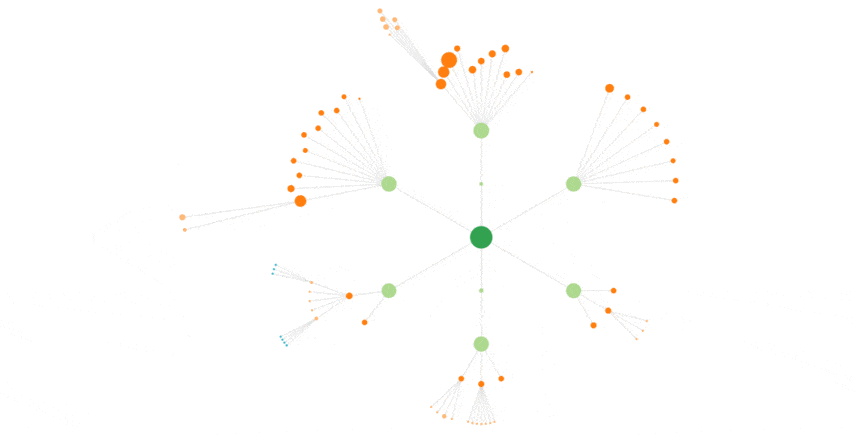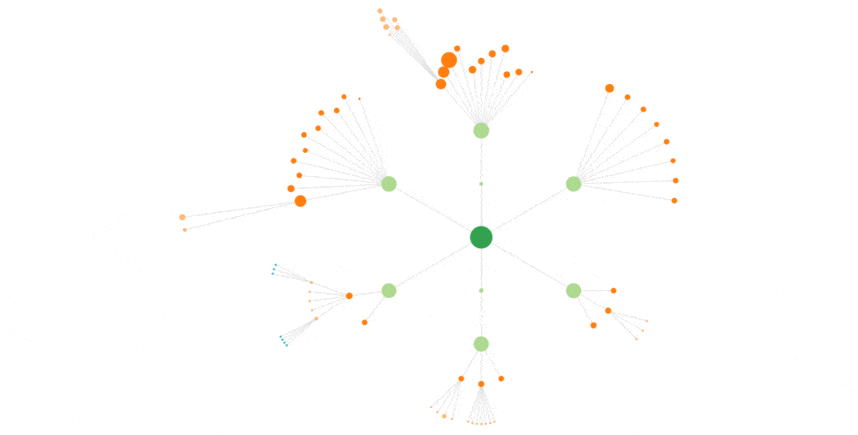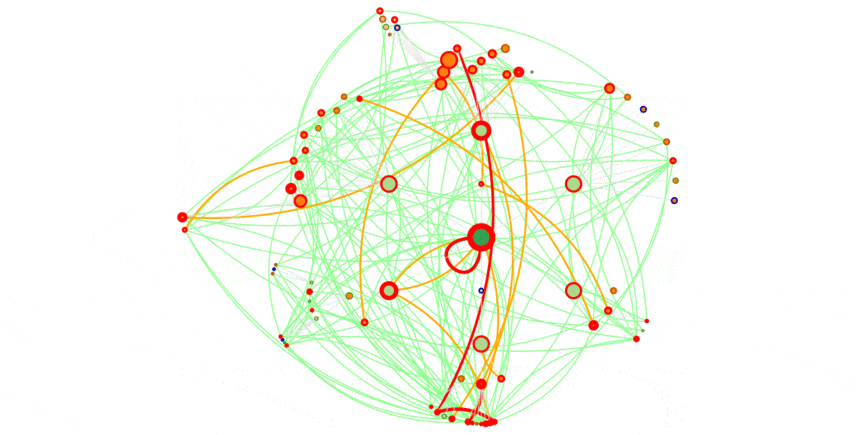
Less shades, a more chaotic behavior than Googlebot’s.
You can see the same on the graph views :
A week for bing, to compare with the same week for Google, first graph of this article.
Let’s animate…
The Sem Eye interface allows the replay of the sessions, including things that are not in the Sem Eye view, such as :
– robots.txt
– 404 or other errors
– resources (css, images)
It looks like that :
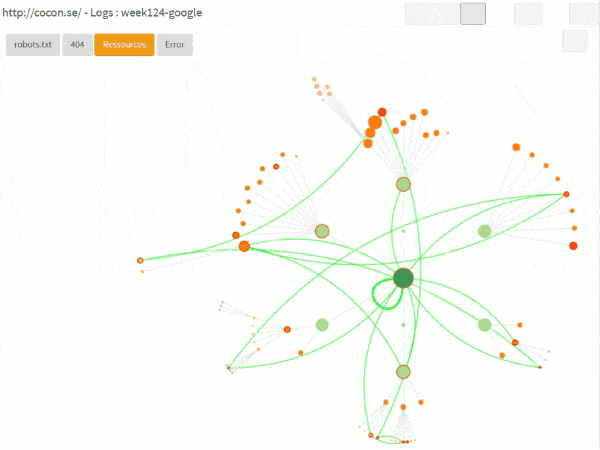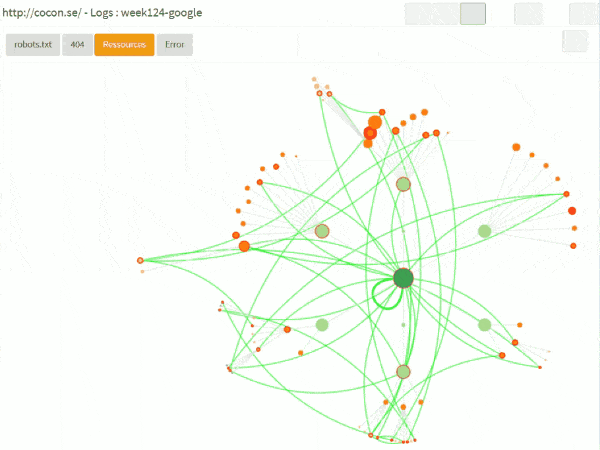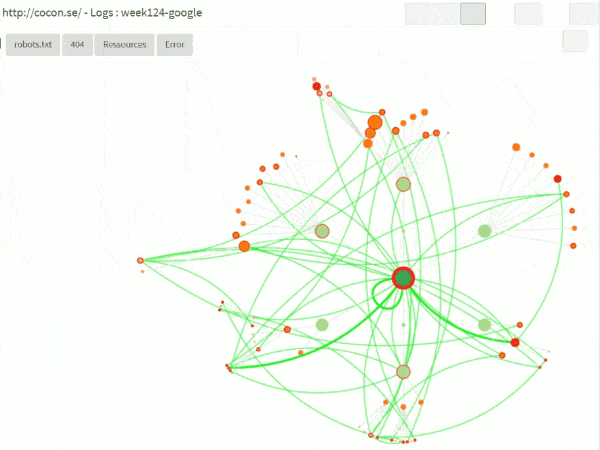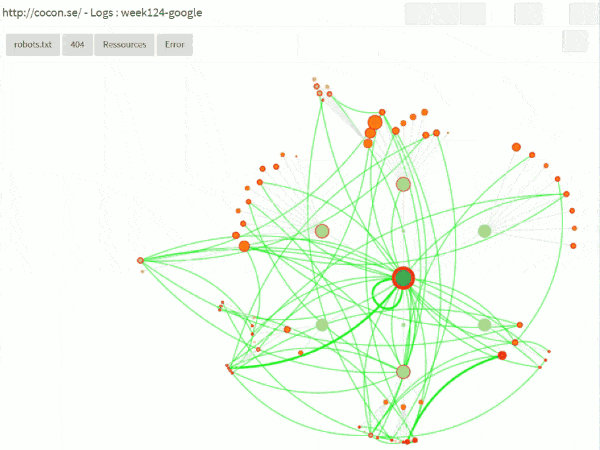
Bots and sessions
Identifying a bot’s session is not as easy as it seems. Especially for small websites.
Bots don’t give a referer. They can wait a long time between a page and the next one, far more than the 30 minutes we use to consider as a reference for human’s sessions.
(They can also been parallelized, that’s a concern)
If we consider the IP address of the bot, the request’s timestamp and a timeout, we are at risk to cut a single session in several one, or to merge several distinct sessions. Moreover, this bot behavior can vary from one site to another, so it’s painful to adjust to a good value.
By looking closely at the sessions however, we can see thet Googlebot f.i., always starts by a call to “robots.txt”.
Only then will it go further (or not : if robots.txt sends a 503 back, it won’t crawl more).
That’s why I chose to identify the sessions by taking this parameter into account : a request for robots.txt does start a new session, even if the IP was already know.
With this failsafe, we are able to use a higher timeout without risk, and it’s ok whatever the website we consider.
SEO usefulness
Of course, tracking the bots activity on his website gives much information.
With a simple statistical log analysis, we can gather a few metrics :
– ignored pages
– pages that are crawled too often, without reason
– 404, other errors
– pages that have changed, but are not crawled
…
However, by merging those individual data (and not just the global statistics) to the SEM Eye view of the website, we got a much more precise interpretation, because we display the data in a known and stable context : the hierarchical vie of the site structure.
The difference between what the search engine crawler is supposed to do, and what it really does, alerts on internal linking errors, crawl obstacles for a specific bot…
Of course, what’s been done here for the bots, we can do as well for human visitors. That again is very enlightening, and we’ll talk more about that in a next article.
Wanna see you website like Googles sees it ? Please give it a try : SEM Eye is still in its infancy, but already usable.
Create your account at https://self.sem-eye.com
References :
The french version of this article on cocon.se : Analyse des bots
@VincentTerrasi’s article (to come)